


How does Forecasting Work in Daisho?
Forecasting in Daisho uses regression underneath the hood, with one very crucial difference: the assumption is that time is the most important driver, and one only needs to explain the difference.
So what do we mean when time is the most important driver?
We assume periodicity + long-term trends + auto-regression are likely to explain most of the outcome. For example, if the long-term growth in the outcome is 2%, its only fair to assume that continues to grow at 2%. Similarly, a low month might typically be followed by a high month just as a smoothening process. We handle the first using long-term trends, and the second using auto-regression. The outcome might also be periodic, e.g., ice-cream sales which always crest in the summer, and are rather low in the winter. We handle this using periodicity.
Time is the most important driver
What's the data required? What's the pre-processing required?
The forecasting workflow assumes that the data is a time-series. All you need to tell us are the outcome variable, the time-stamp column. Daisho does the rest.
So what's the rest that Daisho does?
- Daisho automatically extracts the impact of time on ALL variables in the data - not just outcome variable. Daisho automatically figures out what's the long-term trend (if any), and the periodicity pattern (if any) for each column in the data, and builds time-independent columns.
- Daisho then fits regression models based on time-independent columns. Note that we are making the drivers also time-independent. To understand why that's important, consider impact of temperature on ice-cream sales. The same temperature - say 30 Degrees Centigrade - might be considered too hot for winter leading to increased sales, and considered pleasant in the summer leading to sales being below normal. We can understand this only when we make temperature time-independent.
Generating Time-Independent Columns is the Key
What Insights are Available?
Baselines Based Solely on Time for Outcome Variables
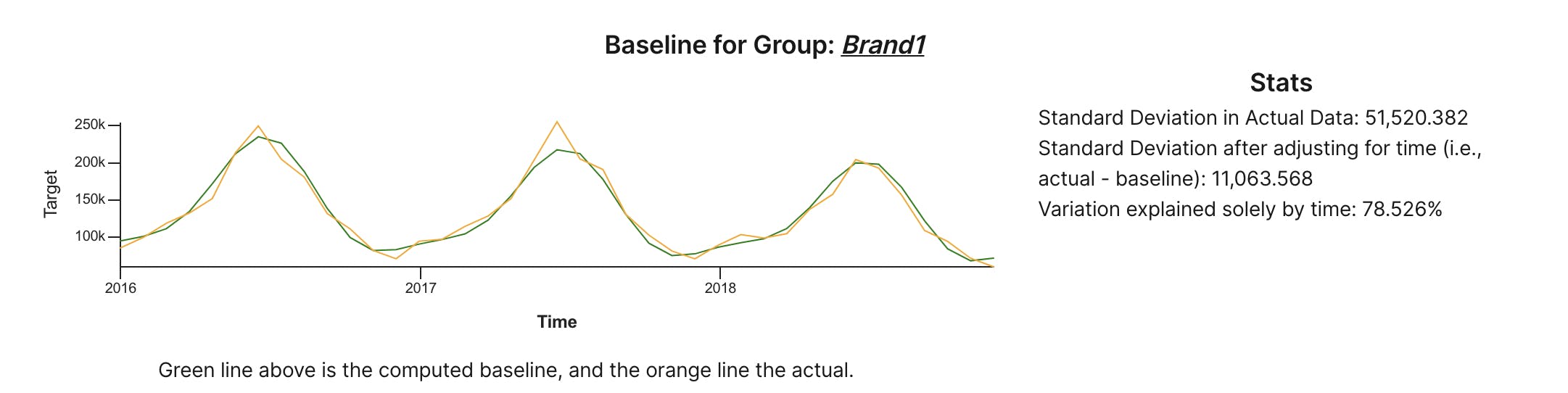
In the above example, while the data itself is quite wavy, Daisho was able to build a rather nice baseline based solely on time. As much as 78% of the variation in raw data goes way due to time alone!
Relationship with Drivers: Raw + Time-Independent
How is the driver related to the outcome? And how does that change when both are adjusted for the impact of time?
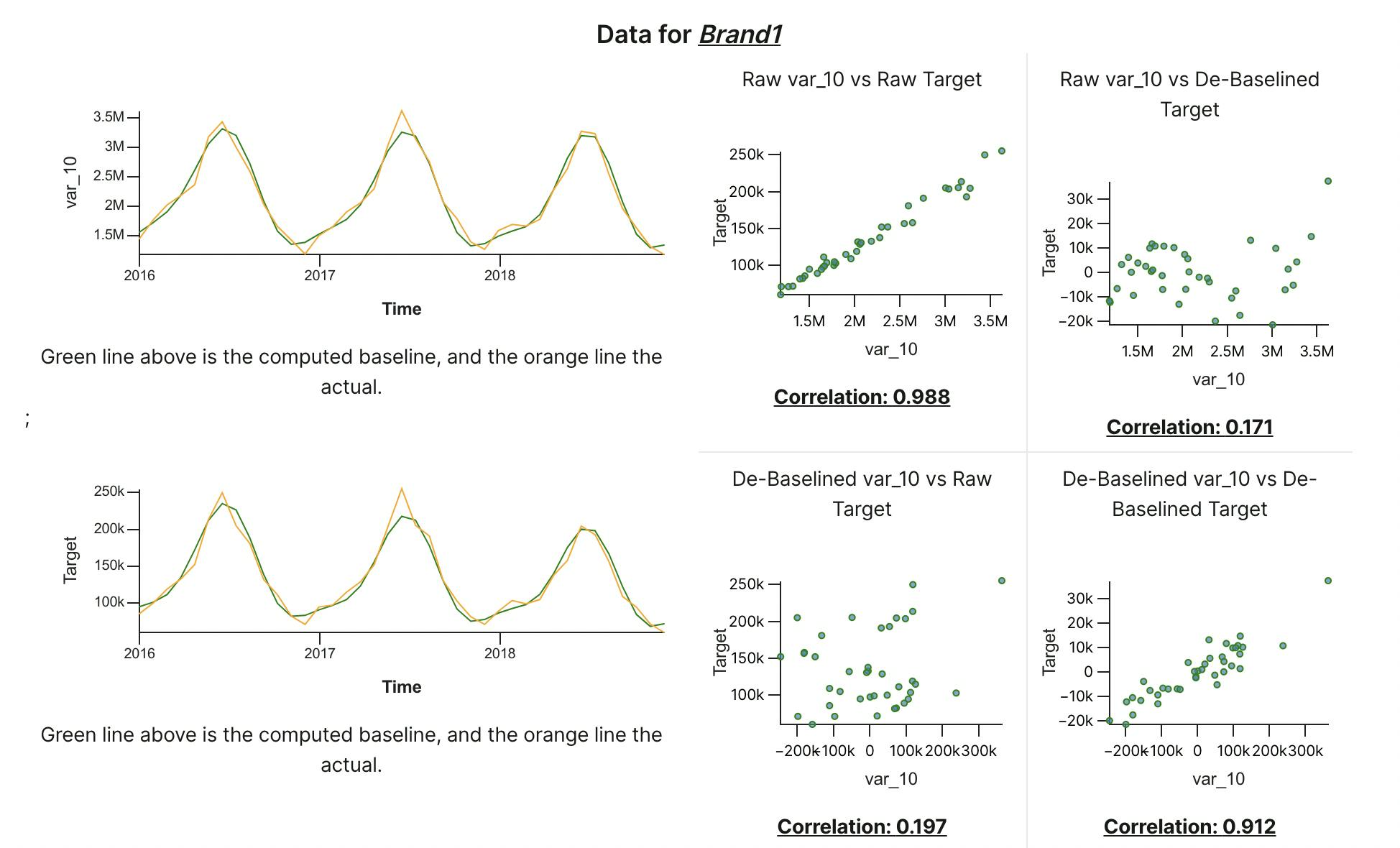
In the above example, the correlation between raw outcome and raw driver is 0.988 - which is rather high. And that remains equally high - 0.912 - even when adjusted for time!
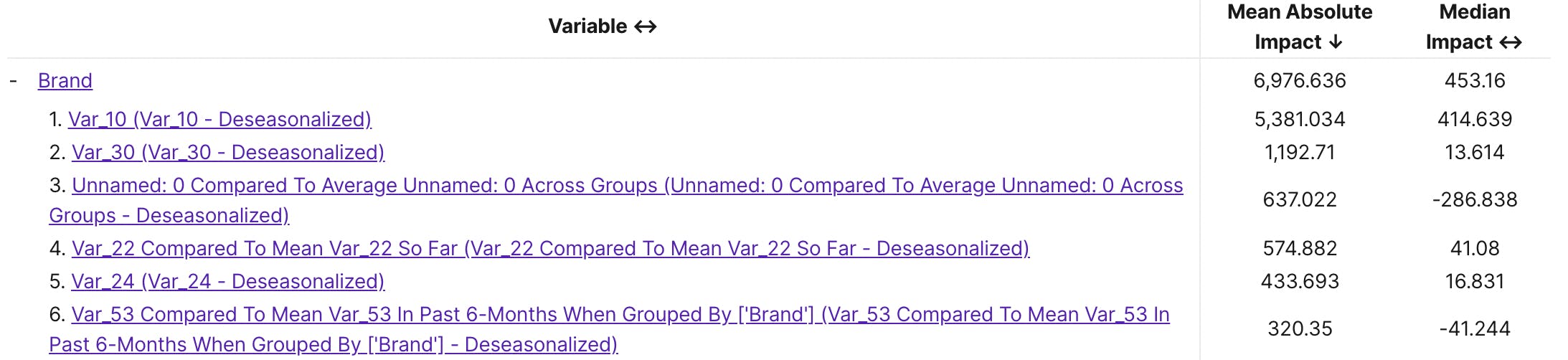
Top Drivers (including interactions), their rankings, and impact on your outcome:
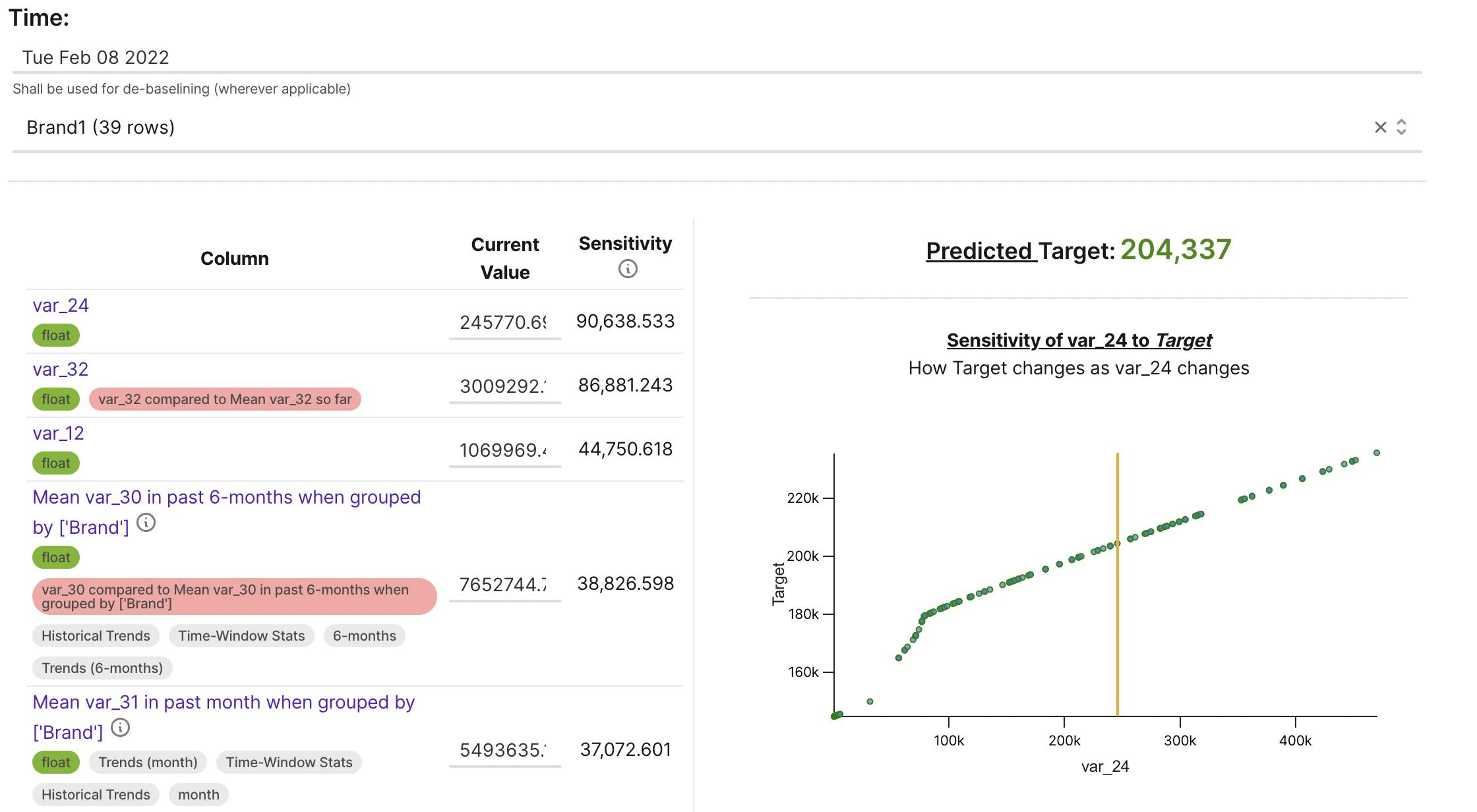
Simulations based on Predictive Models: Change the values, and see predictions change
In addition to these insights, you can also setup your models for predictions, and auto-learn!