


What is Driver Analysis?
Driver analysis, which is also known as key driver analysis, importance analysis, and relative importance analysis, quantifies the importance of a series of predictor variables in predicting an outcome variable. Each of the predictors is commonly referred to as a driver. You can use driver analysis wherever you have a clearly defined outcome. For example:
- What drives sales (outcome variable) of a particular product?
- Under what conditions (drivers) are you likely to get the best yield (outcome variable) in your factory?
- What are the most conducive conditions (drivers) for customer retention (outcome variable)?
- Which loans are likely to result in a default (outcome variable), and under what conditions (drivers)?
Driver analysis tends to be used in two ways:
- A better, and deeper understanding of the business, and
- Predictive analytics to flag likely issues before they occur, or to prioritise actions by impact
What Exactly Does Driver Analysis Do?
The recipe uses the SignalFactory to generate and test a whole bunch of hypotheses. Then, the machine builds predictive models based on the top drivers. A whole bunch of insights are available out-of-the-box:
Top drivers (including interactions), their ranking, and their impacts for your outcome:

Clusters where outcome is most different from the rest of the data - based on raw variables as well as Signal Factory.
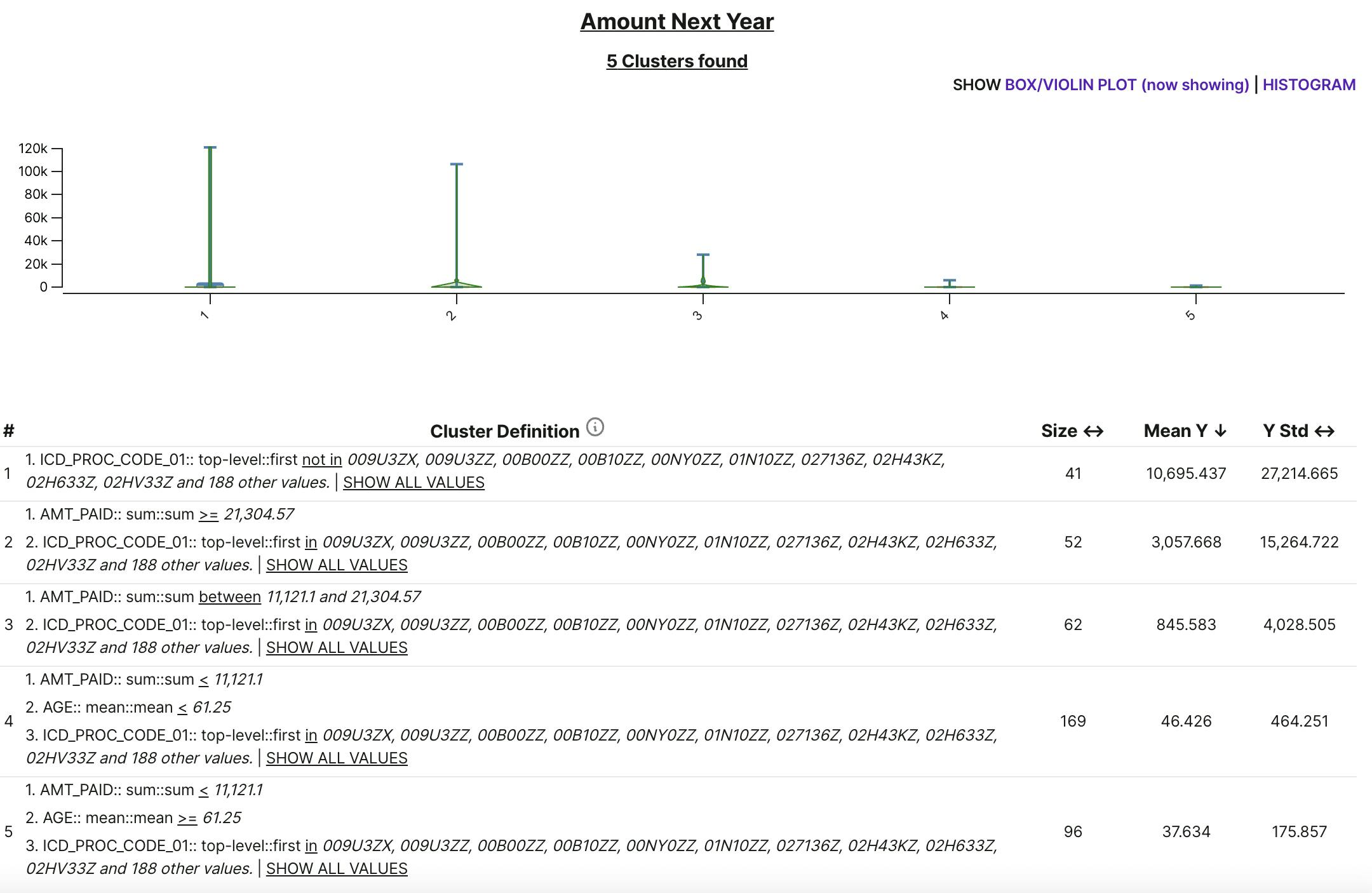
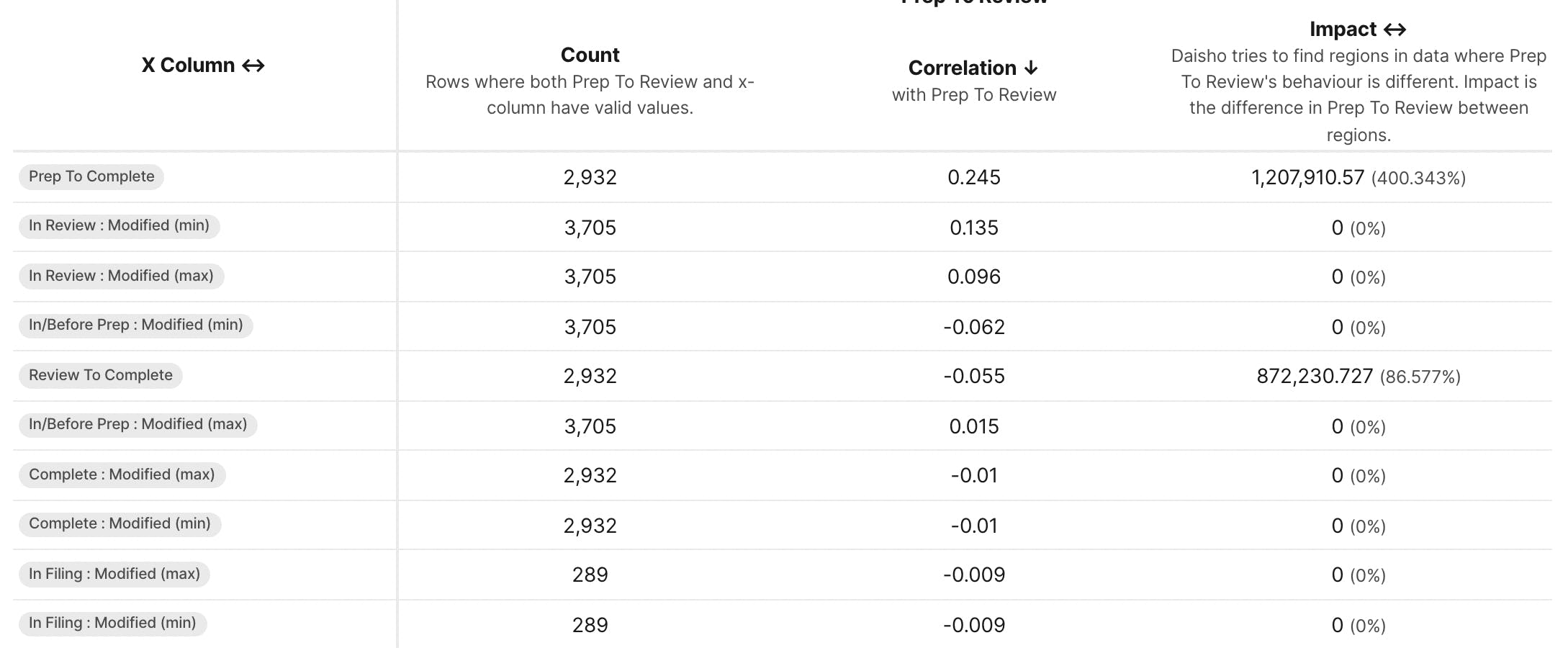
Univariate Analysis - how each column in the data impacts the outcome independently. Correlations, regimes, etc. You can dive deeper into each individual column too
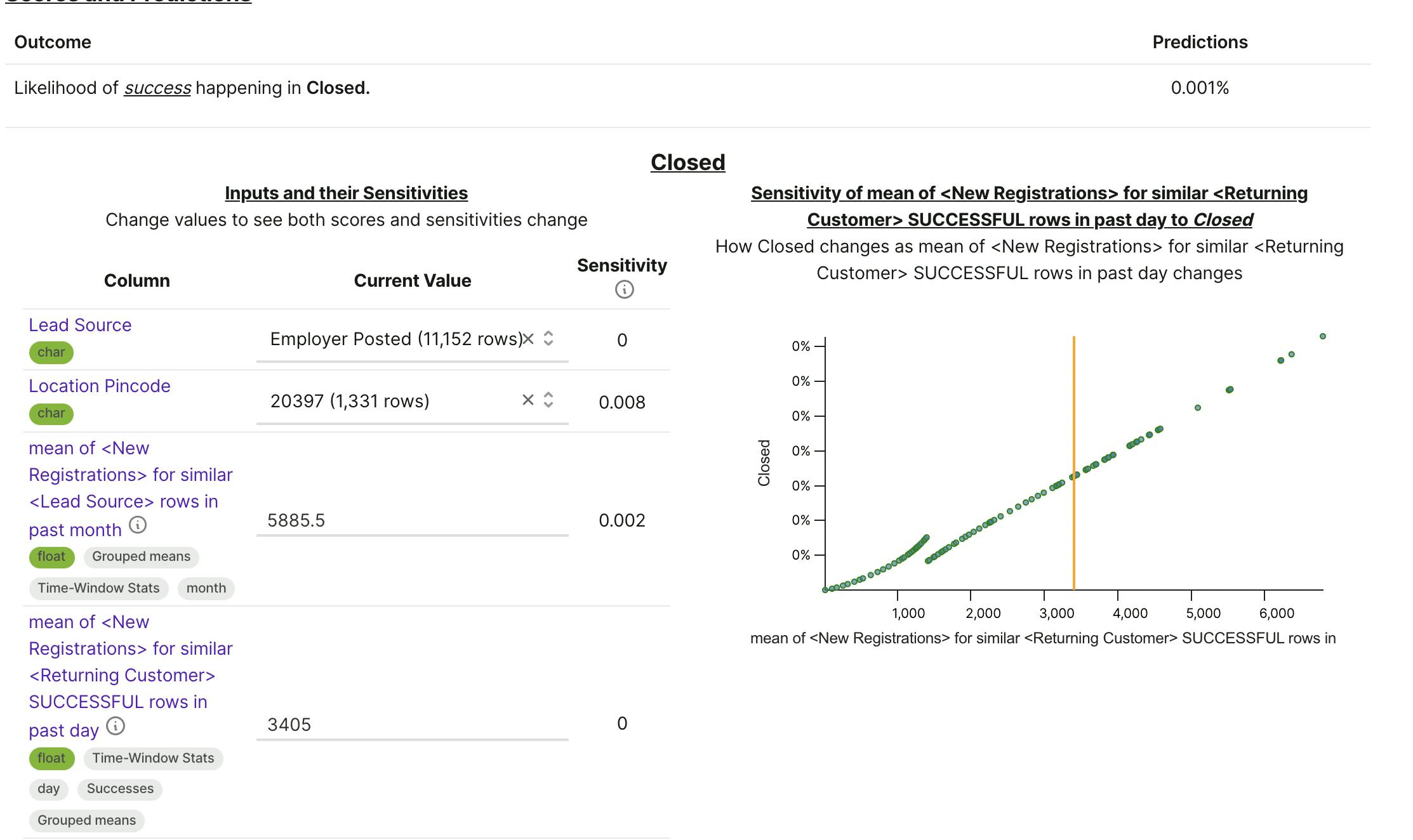
Simulations based on Predictive Models: Change the values, and see predictions change
In addition to these insights, you can also setup your models for predictions, and auto-learn.
What is the data and information required?
The first, and most important information is the outcome variable. Your data MUST contain information related to the outcome variable.
The next question is related to the nature of outcome - this decides the recipe you choose on Daisho. The outcome can be of two types:
- A continuous variable, i.e. a number you want to predict. For example: weekly sales, production yield, etc. Continuous outcomes are typically modelled using regression models. In Daisho, you would be using the Continuous Outcome Driver Analysis recipe. All you need to do is first choose the data, and then point at the correct outcome variable in your data.
- A binary outcome, i.e., a YES/NO (or True/False). For example: customer retention, loan default, machine failure, etc. These kinds of outcomes are analysed using classification models. In Daisho, you would be using the Binary Outcome Driver Analysis recipe. Once you choose the data, you then define conditions for YES/True/Success in your outcome. For example, you might define machine failure (outcome) as temperature (a column) crossing 60 degrees, AND pressure (another column) below 20 psi. You set these conditions in the recipe.
Daisho can build driver analysis on any data where you can define an outcome variable. Daisho assumes ALL columns in the data are potential drivers, and automatically flags the most impactful/powerful ones.
However, do note that Daisho's Driver Analysis analyses the data at a row-by-row level. So for example, if you want to find drivers for weekly sales, and the data you have is transaction data, this is not the right recipe. You have two options: either aggregate your data into weekly format and then use this recipe, or use the Time-Series Analysis recipe on Daisho.
What's Available Now?
We got a bunch of insights already here. Predictive models, clusters, univariate analysis, etc. Once you build models, you can also set them up for Predictions, and Auto-Learn. You can then use these models in your regular workflow!
You can even export all the data - including signals from SignalFactory if you wish!